
Göteborgs cykeldelningssystem, Styr & Ställ, är både välanvänt och omtyckt med fler än 2 miljoner uthyrningar totalt. Dock finns det en hel del brister. Dels innebär den stora mängden uthyrningar att det också krävs en stor insats för att förflytta använda cyklar från de mest populära målen till de mest populära startpunkterna. Detta görs idag genom att med små lastbilar köra runt för att flytta cyklarna från ena sidan av staden till den andra. Min kollega, Fredrik, skrev för ett tag sedan ett ingående inlägg om just omfördelningen och att den faktiskt innebär att det är klart mer miljövänligt att ta spårvagnen än cykeln, om man tar hänsyn till koldioxidutsläppen från lastbilarna som flyttar cyklarna, intressant!
Att en omfördelning behövs är det ingen som motstrider, men det är viktigt att den görs på ett bra sätt, framförallt för att undvika att stationer blir tomma och fulla. För att se vidare diskussion om just servicegraden, se tidigare inlägg.
I detta inlägg kommer jag istället fokusera på att ta fram en matematisk modell för att avgöra hur sannolikt det är att en station kommer bli tom eller full inom 15 minuter. En sådan indikator är något som borde kunna användas som direkt feedback både till användare och lastbilschaufförer och på så sätt förbättra servicen och nöjdheten med systemet.
Flöden mellan stationer
Varje dag görs nästan 4000 uthyrningar av cyklar, vilket måste kompenseras genom att flytta 300-400 cyklar mellan de olika stationerna med hjälp av ungefär 50 stopp med lastbil. Om vi kollar på figuren nedan kan vi se ett tydligt flöde av cyklar från Guldheden, Chalmers och Johanneberg ner mot centrum. Det är uppenbarligen lockande att ta cykeln ner för berget. Men även i centrum finns det vissa stationer som har ett utflöde av cyklar, till exempel Nils-Ericsson terminalen och Kungsgatan/Televerket.
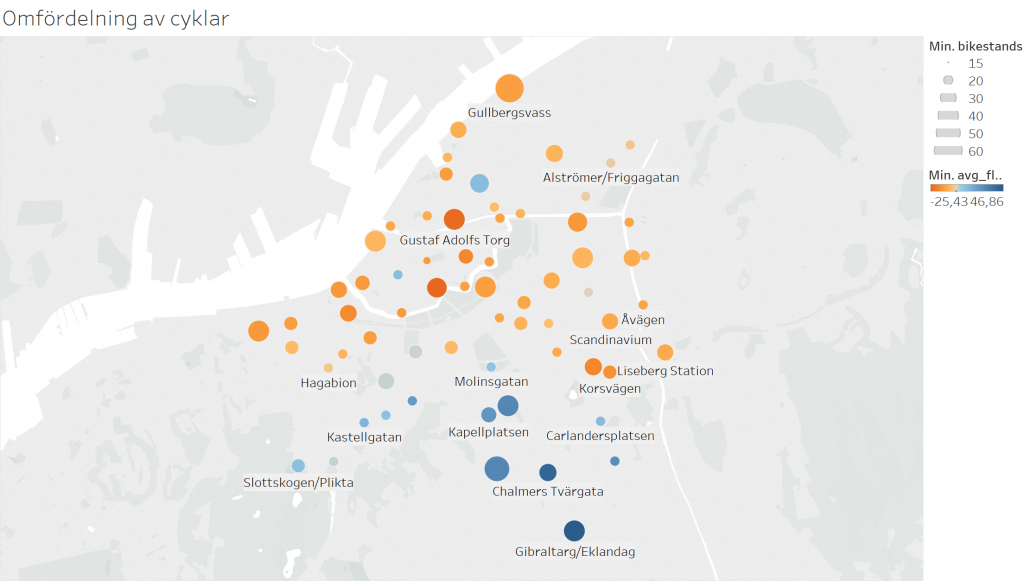 Karta visandes flödet av cyklar in och ut från stationerna. Blå-skala indikerar ett utflöde medan röd-skala indikerar inflöde. Storleken på prickarna korresponderar mot stationens storlek.
Karta visandes flödet av cyklar in och ut från stationerna. Blå-skala indikerar ett utflöde medan röd-skala indikerar inflöde. Storleken på prickarna korresponderar mot stationens storlek.
Vissa stationer, till exempel Grönsakstorget och Gustav Adolfs torg, har ett inflöde av närmare 25 cyklar om dagen, medan andra, till exempel Gibraltargatan har ett utflöde uppemot nästan 50 cyklar per dag. Det skulle således krävas väldigt stora stationer för att det inte skulle behövas frekventa omfördelningar till de stationerna.
In- och ut-checkning
I sig är det inga problem med omfördelningen, det är endast ett sätt att leverera den tjänst som cykelsystemet utgör, men det kan vara frustrerande att, som användare av systemet, komma till en station utan några lediga cyklar att tillgå, eller kanske än värre, att komma fram med sin hyrda cykel och inte kunna lämna tillbaka den för att stationen är full.
Att skapa en perfekt omfördelning av cyklarna för att totalt minimera dessa fall är långt utanför denna artikels fokus. (Även om det givetvis också skulle kunna göras, givet tillgång till tillförlitlig och fullständig data över systemet.) Istället skall vi fokusera på att ta fram en indikator som säger om det är sannolikt att en given station kommer vara full eller tom om 15 minuter. Tanken med det är att både användarna och lastbilschaufförerna skall ha nytta av det, då 15 minuter borde vara tillräckligt för användaren att planera sin resa och för lastbilschauffören att hinna köra till stationen och lasta av/på cyklar. Båda för att maximera nöjdheten med systemet.
Val av modell
Både inför en analys av ett dataset och under konstruktion av prediktion, klustring eller matematiska modeller krävs att rätt modell används för att uppnå bra resultat. För att skapa cykelindikatorn krävs en statistisk modell som tar hänsyn till stokastiska fluktuationer och som kan ange sannolikheten för systemet att befinna sig i ett givet tillstånd. Ett passande val, som uppfyller dessa krav är att modellera cykelantalet på varje station som en Markovprocess.
Markovprocesser
En Markovprocess är en modell för att modellera stokastiska processer. Den utgår från några grundläggande antaganden och utifrån det kan man skapa både kraftfulla och effektiva modeller för att förutspå tillståndet av olika typer av system.
Det största och viktigaste antagandet är att processen är oberoende av tidigare tillstånd. Endast det nuvarande tillståndet krävs för att fullständigt beskriva sannolikheten för nästkommande tillstånd. Ett typiskt exempel på en Markovprocess är en vanlig kö. Varje ny kund kommer till kön med oberoende ankomsttider. Eftersom en kund som ankommer till affären inte har gått dit beroende på vilka kunder som redan står i kön, så är det alltså att betrakta som att köns framtida tillstånd är oberoende av tillstånd längre bak i tiden än det nuvarande. Kundernas ankomsttider modelleras i sin tur med en statistisk modell, vanligen som en Poisson process med en tidigare uppmätt ankomsttakt. Poisson processer är i sin tur en välanvänd statistisk modell som kan användas för att till exempel modellera hur regn faller på en yta.
Markovprocesser kan användas till att modellera långt mer komplexa processer än våra cykelstationer, men de är också väldigt användbara för dessa enklare fall. Eftersom stationerna (eller köer för den delen) inte bara får in cyklar utan även lämnar ut dem, så kan vi modellera det som en så kallad födelse- och dödsprocess, som är en undergrupp av Markovprocesser (engelska: birth and death process). Givet ett tillräckligt kort tidsspann finns det bara tre möjliga utfall som hinner hända:
- En cykel lämnas in.
- En cykel hämtas ut.
- Inget händer.
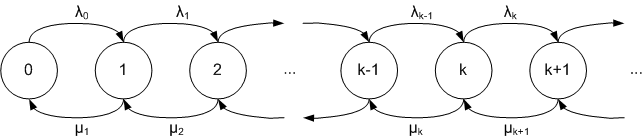 Födelse och dödsprocess beskriven som en kedje. Från varje tillstånd (cirklar) så kan systemet flytta sig uppåt med en sannolikhet λ och nedåt med en sannolikhet μ.
Födelse och dödsprocess beskriven som en kedje. Från varje tillstånd (cirklar) så kan systemet flytta sig uppåt med en sannolikhet λ och nedåt med en sannolikhet μ.
Detta innebär att vi kan modellera förändringen från varje tillstånd av cykelstationen genom att betrakta endast dessa tre utfall. När något av de utfallen har skett så är vi tillbaka i ett nytt tillstånd och kan börja om igen med modelleringen.
För att då kunna betrakta längre tider än "korta", så kan man stapla flera sådana korta tidsspann på varandra och på så sätt skapa en modell som även sträcker sig över de infinitesimala tidshorisonterna som krävs för den konceptuella framtagningen av modellen.
Markovprocessen för Styr & Ställ
Nog om detaljerna kring modellen. I vårt fall behöver vi endast ta fram de olika ankomsttakterna och sedan kan vi implementera en generell lösningsmetod för Markovprocessen i till exempel python.
De två processer som vi förhåller oss till är ankomsten av en användare, som vill checka ut en cykel, samt inlämningen av en cykel. Båda dessa processer antar vi sker oberoende av varandra på varje given cykelstation och att de har en ankomsttid som är liknande för samma timme på samma veckodag varje vecka. För att ta fram dessa ankomsttider kan vi alltså räkna fram hur många cyklar per timme som normalt ankommer och lämnar en station under varje timme under en hel vecka. Dessa medeltal blir så våra ankomsttakter för de olika stationerna som en funktion av tid på dygnet och vilken veckodag vi betraktar.
Med hjälp av dessa kan vi sedan konstruera och lösa en Markovprocess och på så sätt ta fram sannolikheten för att finna en station med x antal cyklar vid tiden t + 15 minuter givet att stationen har y cyklar vid tiden t.
Vidare behöver vi en definition av vad som är att betrakta som en full eller tom station. För fallet med indikatorn valde jag att sätta ett gränsvärde på 20 %. Så om stationen har en sannolikhet på över 20 % för att ha antingen 0 eller 1 cykel respektive N eller N-1 cyklar (där N är antalet cykelställ), så är flaggar indikatorn att det finns en risk för att uppnå dessa randvärden.
Resultat
Bilden nedan visar det mest sannolika utfallet tillsammans med det faktiska utfallet för Folkungagatan den 7 juni 2016. I den undre grafen kan vi även se den indikerade sannolikheten för det utfallet.
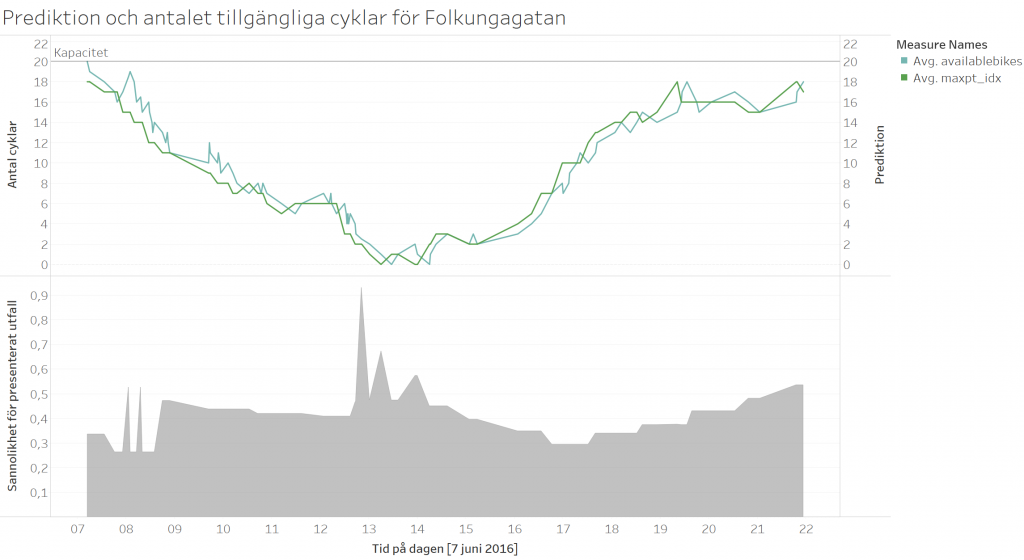 Det mest sannolika utfallet från modellen (orange) tillsammans med det faktiska utfallet (grå). För Folkungagatan den 7 juni. Den undre grafen visar modellens sannolikhet för det indikerade mest sannolika utfallet.
Det mest sannolika utfallet från modellen (orange) tillsammans med det faktiska utfallet (grå). För Folkungagatan den 7 juni. Den undre grafen visar modellens sannolikhet för det indikerade mest sannolika utfallet.
De två linjerna följer varandra ganska väl, med den modellerade liggandes lite före den faktiska både på upp och nedgången. Vi kan även se att alla tillstånden har en förhållandevis låg sannolikhet för att inträffa, vilket också reflekteras i att kurvorna sällan ligger rakt uppe på varandra.
Efter denna första analys kan vi sluta oss till att modellen ger rimliga svar jämfört med utfallet. Speciellt eftersom det är en stokastisk modell, så kommer vi aldrig få det faktiska utfallet utan bara sannolikheterna för varje utfall. Men bilden ovan indikerar att det finns någon styrka i modellen.
Vidare kan vi kolla på bilden nedan, som visar antalet cyklar på Berzeliigatan den 2 juni tillsammans med vår konstruerade indikator. Redan klockan 13 ser vi en indikation på att det finns en risk att stationen skall bli full. Sen hämtas det dock ut ett antal cyklar, men väl vid 16 så blir stationen full, vilket även indikatorn håller med om. I detta fall skulle man dels kunna använda indikatorn för att redan klockan 13 ta ut ett antal cyklar och så helt undvika att stationen blir full på eftermiddagen alternativt använda de större indikatorerna fram på eftermiddagen för att styrka beslutet att det är värt att flytta cyklar från den fulla stationen eftersom det är låg sannolikhet att användare kommer komma för att hämta ut fler cyklar den närmsta tiden.
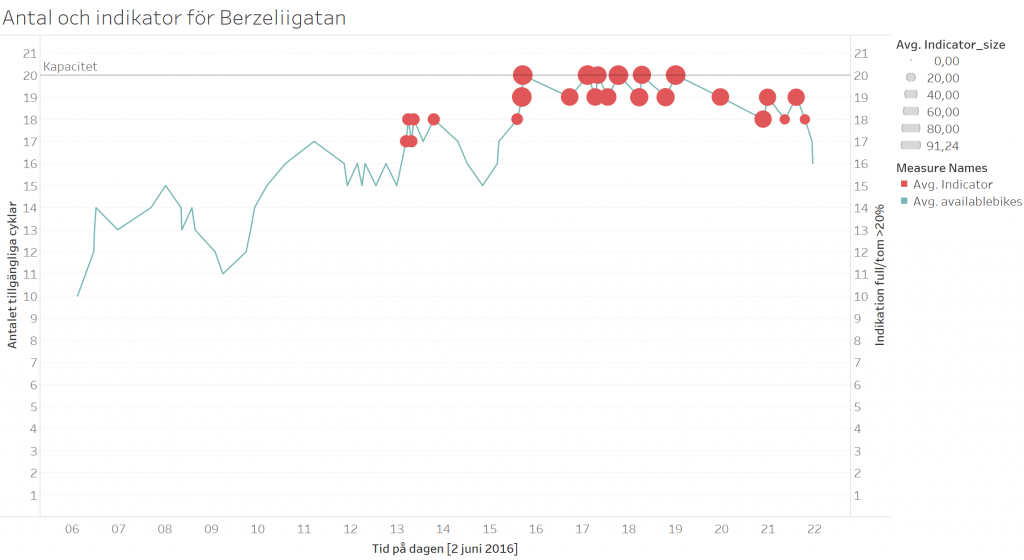 Indikatorn (de röda prickarna) och antalet tillgängliga cyklar (den grå linjen) för Berzeliigatan den 2 juni 2016. Större prickar visar på en större sannolikhet för att stationen kommer att bli full/tom.
Indikatorn (de röda prickarna) och antalet tillgängliga cyklar (den grå linjen) för Berzeliigatan den 2 juni 2016. Större prickar visar på en större sannolikhet för att stationen kommer att bli full/tom.
Om vi betraktar ytterligare ett exempel, givet i bilden nedan, så ser vi återigen fall då indikatorn kunde använts för att minimera tiden med en full station. I detta fallet är det stationen på Drottningtorget den 23 augusti som vi ser. Här är det ett svårare fall eftersom stationen är tom på förmiddagen men sedan fylls under eftermiddagen. Dock flaggar indikatorn i tid för båda dessa randvärden för att en lastbil mycket väl skulle ha tid att lämna av cyklar på morgonen och hämta cyklar på eftermiddagen.
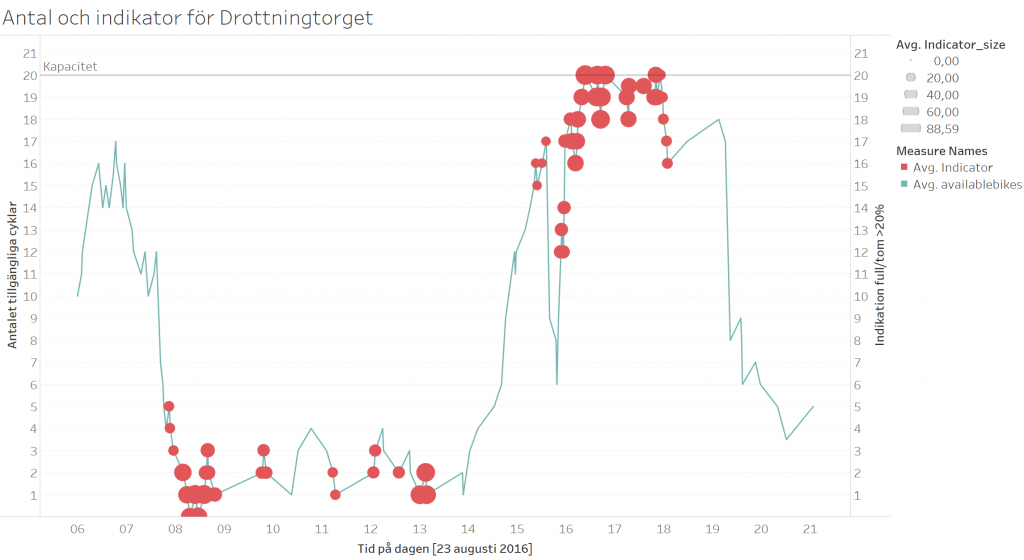 Indikatorn (röda prickar) och antalet tillgängliga cyklar (grå linje) för Drottningtorget den 23 augusti. Prickarnas storlek visar sannolikheten för att stationen skall bli full/tom.
Indikatorn (röda prickar) och antalet tillgängliga cyklar (grå linje) för Drottningtorget den 23 augusti. Prickarnas storlek visar sannolikheten för att stationen skall bli full/tom.
På en aggregerad nivå vi kan också se några stationer som i genomsnitt alltid har en indikator som är flaggar samma tid över alla dagar. Ett exempel på detta ges i bilden nedan där vi ser Nils-Ericsson terminalen. På förmiddagen är den genomsnittliga sannolikheten för att stationen skall bli tom nästan 20 % medan det på eftermiddagen är nästan 25 % sannolikhet att finna stationen tom.
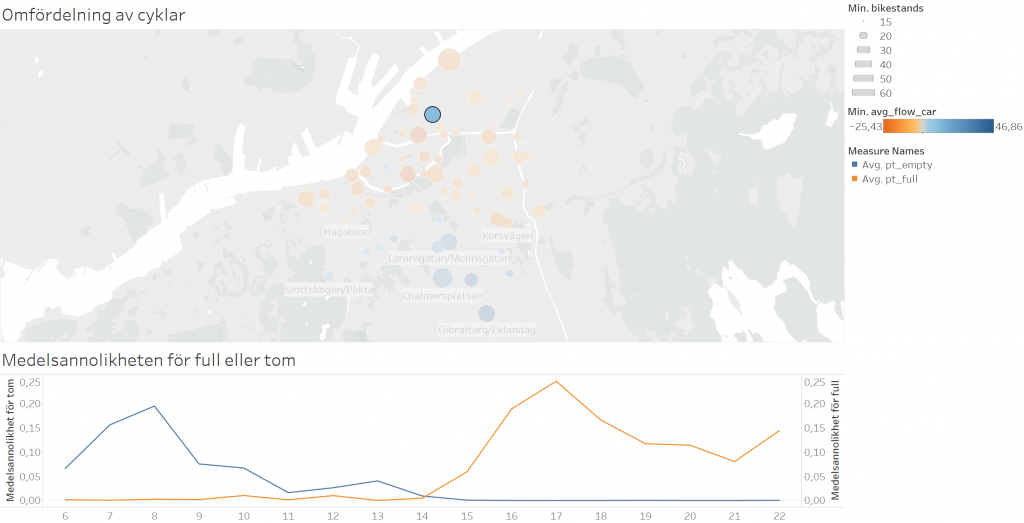 Medelsannolikheterna för att finna stationen full (blå) eller tom (orange) över dygnet för Nils-Ericsson terminalen.
Medelsannolikheterna för att finna stationen full (blå) eller tom (orange) över dygnet för Nils-Ericsson terminalen.
Slutsatser
Genom att modellera cykelantalet i stationerna som en Markovprocess kan vi skapa ett hjälpmedel för att driva ett bättre och mer användarorienterat Styr & Ställ. Indikatorn flaggar i tid för att en station kan komma att bli tom eller full och möjliggör att cyklarna kan omfördelas för att undvika den situationen. Indikatorn kan även användas för att identifiera de mest kritiska stationerna samt att besluta om det är ett bra beslut att flytta cyklar från en full eller en tom station eller om användarna av Styr & Ställ inom kort kommer att lösa det problemet själva.
Felkällor och begränsningar
Den största felkällan med denna modellen torde vara att statistiken vi har tillgång till innefattar att stationerna är fulla och tomma vissa tider. Det innebär att vi kan få en viss underskattning av ankomsttakterna eftersom användare egentligen skulle vilja checka ut en cykel när det inte finns någon eller tvärt om. För att hjälpa upp det skulle det krävas att systemet körs med ett större antal lastbilar för att under en testperiod samla in data från när systemet är helt användarstyrt, det vill säga att alla inlämningar och utcheckningar som är efterfrågade kan göras. Alternativ två är att samla data under en mycket lång period och låta statistiken själv jämna ut eventuella felskattningar. Detta i sin tur kräver dock att det inte görs systematiska fel med förflyttningarna av cyklar så att samma stationer har samma problem vecka in och vecka ut.
Det grundläggande modellantagandet med oberoende mellan ankomsterna finns ingen anledning av ifrågasätta, dock skall sägas att framtagningen av ankomsttakterna i sig troligtvis kan förbättras. Den stora begränsningen här ligger troligtvis i den begränsade upplösningen på ankomsttakterna, där de räknats ut på timbasis. Både på morgonen och eftermiddagen är det troligtvis stora variationer ner på en fjärdedels timme, som här inte fångas upp av modellen.
Externa påverkansfaktorer är här heller inte med. För att få en säker och tillförlitlig modell behöver man säkerställa att de största påverkansfaktorerna är fångade med modellen. Till exempel är vädret troligtvis en sådan faktor. Så för att förbättra modellen skulle man till exempel kunna ta med temperatur och om det regnar eller inte vid grupperingen och framräknandet av ankomsttakter.
En av de roligaste uppgifterna som Data Scientist är just detta, att identifiera en passande modell och försöka leverera nya insikter eller verktyg för att förbättra en verksamhet.
Om ni undrar mer om hur matematisk modellering kan användas för att förbättra Er verksamhet, tveka inte att höra av er!
Läs mer:
Del 1 – Data Science i praktiken
Del 2 – Hur tillgängligt är Styr & Ställ?
Del 3 – Styr och ställ stationen på rätt platss
Del 4 – Hur Data Science kan rädda miljön
Avancerad analys förstår Göteborgs bostadsmarknad
The Data Scientist


