
Sedan datorkommunikationens begynnelse har vi haft en förkärlek till request/reply som integrationsmönster. Från början var det RPC, sedan kom CORBA, DCOM, SOAP Web Services och REST. Alla med fokus mot en server som tillhandahåller en tjänst och en klient som frågar och får svar. Många gånger har vi verkligen ansträngt oss för att jobba efter just detta mönster, t.ex. genom att bygga upp en lokal cache för att inte behöva överbelasta servern med frågor. Visst är det ett väldigt användbart mönster, men det har blivit så slentrianmässigt sätt att realisera på att man nästan glömt bort att det finns en annan modell – nämligen publish/subscribe.
Snabb introduktion till publish/subscribe
Själva namnet publish/subscribe beskriver egentligen mönstret väldigt konkret. Som avsändare av information publicerar man meddelanden och som mottagre av information prenumererar man och blir notifierad när det finns information att tillgå (d.v.s. ”push” i stället för ”pull”). Det enklaste och vanligaste sättet att strukturera meddelanden är genom så kallade ”topics”, eller ämnen. Publicering sker med ett visst ämne och som prenumerant prenumererar jag också på ett visst ämne.
I integrationssammanhang pratar man ofta om lös koppling som en dygd, och publish/subscribe har per definition en lösare koppling än request/reply. Som producent har jag ingen aning om vem som konsumerar mina meddelanden, och som konsument tar jag emot information utan att behöva känna till detaljer om vem som producerat den. Detta innebär t.ex. att man kan lägga till både nya producenter och nya konsumenter utan att påverka tidigare uppsatta parter.
Den extra infrastruktur man använder sig av för att erbjuda publish/subscribe brukar skötas genom en så kallad message broker. Denna erbjuder som regel garanterad leverans och dirigering av meddelanden, vilket gör att man kan fokusera på informationsutbytet snarare än att lägga energi på robust överföring av själva informationen.
Exempel från verkligheten
Jag har själv arbetat mycket inom retail – och här finns det goda exempel på hur publish/subscribe är ett mycket mer passande mönster än request/reply. Antag först följande scenario: En butikskedja med hundratals butiker och tusentals kassaplatser arbetar med central bokföring. Det betyder att vartenda försäljningskvitto ska skickas löpande in till en central huvudbok. Inom all konsumenthandel är det också fullständigt otänkbart att inte kunna ta betalt – om nätverket går ned ska åtminstone försäljningen rulla på som vanligt.
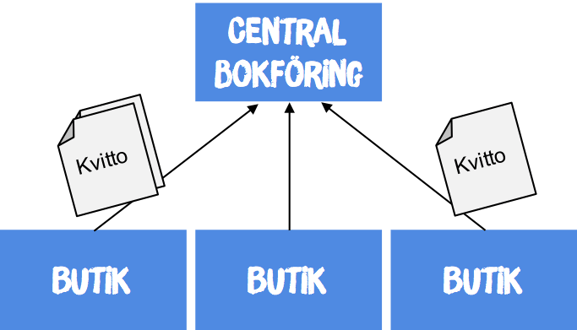 Om man skulle använda request/reply för att skicka kvitton till den centrala bokföringen skulle man hamna i ett tillstånd där kassan låser sig om inte nätverket är tillgängligt. Detta vore helt oacceptabelt, så i stället publicerar kassorna sina kvittotransaktioner till en icke-blockerande köhanterare som garanterar leverans till den centrala bokföringen. Om nätverket skulle vara nere kommer då allt att läggas på kö till dess man åter har en anslutning tillgänglig.
Om man skulle använda request/reply för att skicka kvitton till den centrala bokföringen skulle man hamna i ett tillstånd där kassan låser sig om inte nätverket är tillgängligt. Detta vore helt oacceptabelt, så i stället publicerar kassorna sina kvittotransaktioner till en icke-blockerande köhanterare som garanterar leverans till den centrala bokföringen. Om nätverket skulle vara nere kommer då allt att läggas på kö till dess man åter har en anslutning tillgänglig.
Det hela blir ännu mer intressant när man inser att kvitton används till så mycket mer än bokföring. Exempelvis sker nedräkning av lagersaldo som en direkt konsekvens av försäljning. För att hålla reda på lagersaldo behöver man bara lägga till lagerhanteringssystemet som prenumerant på kvittoflödet och räkna ned lagersaldo per butik och såld vara utifrån kvittotransaktionerna
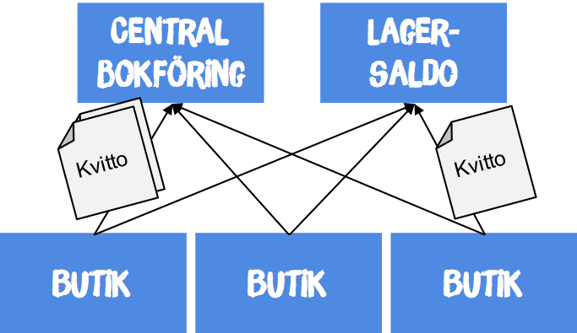 Om man tycker att det börjar se spretigt ut med alla sambandspilar ska man ha i åtanke att det enda man håller reda på själv är vilket ämne man publicerar och prenumererar på – den underliggande meddelandehanteraren tar hand om att lösa upp alla samband.
Om man tycker att det börjar se spretigt ut med alla sambandspilar ska man ha i åtanke att det enda man håller reda på själv är vilket ämne man publicerar och prenumererar på – den underliggande meddelandehanteraren tar hand om att lösa upp alla samband.
När man har en central master för lagersaldo, vilket är trenden för kedjor inom detaljhandel, betyder det att man också behöver läsa lagersaldot från den centrala källan, både för sin egen, men ofta också för andra butiker i kedjan. Här skulle man absolut kunna tänka sig att kassan frågar den centrala funktionen varje gång man är i behov av att veta ett lagersaldo, men när man pratar om flera tusen kassor i en kedja som var och en frågar efter lagersaldo kan det snabbt medföra tiotusentals lagersaldofrågor per minut. Därför är det vettigt att lösa även lagersaldo med ett publish/subscribe-mönster.
De lokala kassorna prenumererar på lagersaldoförändringar, och den centrala miljön behöver enbart publicera lagerrörelserna när de inträffar.
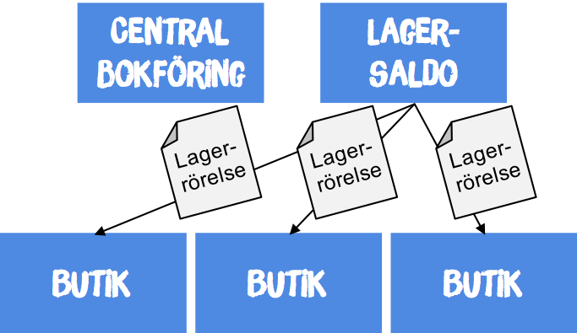 Den lokala kopian på alla butikers lagersaldon behöver inte bli större än några hundra megabyte, även om man har ett tusental butiker och runt 10 000 artiklar. Varje enskilt meddelande kräver bara några få bytes. Om man pratar om riktigt stora kedjor kan man tänka sig att bara läsa in lagersaldo för de butiker som ligger geografiskt nära för att hålla nere på cache-storleken.
Den lokala kopian på alla butikers lagersaldon behöver inte bli större än några hundra megabyte, även om man har ett tusental butiker och runt 10 000 artiklar. Varje enskilt meddelande kräver bara några få bytes. Om man pratar om riktigt stora kedjor kan man tänka sig att bara läsa in lagersaldo för de butiker som ligger geografiskt nära för att hålla nere på cache-storleken.
På samma sätt är det sedan väldigt enkelt att lägga till en e-handel till lösningen – alla butikers lagersaldo kan automatiskt publiceras on-line, enbart genom att man lägger till e-handelssystemet som prenumerant på lagerrörelsemeddelanden. Något som är nästan ännu elegantare är att vi automatiskt försäkrat det centrala lagerhanteringssystemet från att sänkas genom trafikanstorming från internet mot e-handeln.
Avslutande tankar
Syftet med detta inlägg är att uppmuntra till att fundera en extra gång innan man slentrianmässigt väljer request/reply som standardsvar på nästa integrationsutmaning.
Det finns också ett asynkront beteende i hela upplägget som beskrivits. Asynkront är alltid lite svårare att ta till sig, men jag tycker mig också se att modern utveckling går mer och mer mot asynkrona mönster, så jag hyser gott hopp om framtiden.
Och till sist – frågar du mig om vilken message broker som man ska använda rekommenderar jag RabbitMQ – snabb, robust och tillgänglig både som open source och i kommersiell förpackning.

