
Data lake har seglat upp som ett nytt begrepp, är det en hype, en fluga eller kan det vara användbart för mig?
Jag ska försöka förklara konceptet data lake eller datasjö, och jag tänker spara mer tekniska utlägg till kommande bloggposter.
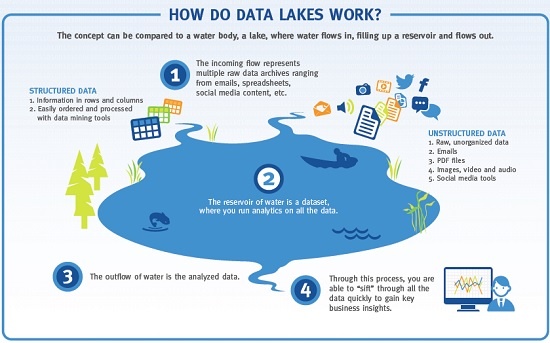
Vad är då en data lake?
En Googlesökning på “data lake” ger en massa svar och följande definition från wikipedia tycker jag är ett lysande förklaring på vad en data lake borde vara:
"A data lake is a large-scale storage repository and processing engine. A data lake provides "massive storage for any kind of data, enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs".
The term was coined by James Dixon, Pentaho chief technology officer. Dixon used the term initially to contrast with "data mart", which is a smaller repository of interesting attributes extracted from the raw data. He wrote: "If you think of a datamart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples."
Här läser du wikipedias definition
Och jag skulle vilja formulera mig aningen mer tekniskt: data lake är ett repository för att lagra en stor mängd rådata i sitt ursprungliga format tills den efterfrågas, först då definierar vi schema och krav.
Själv gillar jag att hitta lämpliga metaforer när jag ska designa och beskriva teknisk arkitektur, det gör det mycket lättare att få personer som inte är tekniska att förstå ofta ganska komplexa tekniker och metoder.
Vattenmetaforen som James Dixon beskriver tycker jag passar väldigt bra med min inre bild av hur en data lake ser ut.
Data lake, något för mig?
- Ska jag kasta bort mitt traditionella DW och ersätta det med en data lake, eller kan jag berika mitt DW med en data lake?
Hur mycket data ska jag lagra i min data lake? - Big Data, "enough data" (alltså tillräckligt med data för att stödja och utveckla verksamheten?
- Är det inte bara ytterligare ett hypat begrepp för att generera en massa konsulttimmar?
- Vi har vår ODS (Operational Data Store), och vad ska en data lake tillföra?
Så många frågor och förhoppningsvis ger vi dig några svar!
De tre främsta fördelarna
- Data self-service för verksamheten som inte behöver vänta på att IT skall leverera informationen i datalagret.
- En värdefull källa för en data scientists datahungriga algoritmer, man kan kalla det en "data sandbox for exploration and discovery".
- Billigare och enklare lagring än att lagra informationen i en relationsdatabas (Hadoop, NoSQL, Azure Data Lake mm), och i datasjön kan du lagra strukturerad och ostrukturerad data.
Kasta inte yxan i sjön bara, det traditionella datalagret med sin "single-version of the truth" har inte försvunnit och bör/kommer inte göra det. Där finns den kvalitetssäkrade informationen som är motorn i att driva verksamheten framåt.
Se också till att din data lake fortsätter vara den friska, klara källan, och inte förvandlas till en "data swamp"
och till slut...
Världen förändras, nya trender kommer och går. Det traditionella datalagret behöver också förnya och förändra sig i takt med att krav och teknik förändras. Ett bra koncept att titta på är då hur en data lake kan komplettera datalagret för att kunna dra mer nytta av informationen som finns. Vi vill så att säga. få en högre verkningsgrad på transformeringen från data till information och kunskap.
Jag vill ge samma råd här som Fredrik Moeschlin gör i sitt inlägg här, börja enkelt och tänk nytta före teknik.
Gillar du så kallade infographics så hittar du en om data lakes här.
God fiskelycka!



