
Många utvecklare har säkert erfarenhet att arbeta med masterdata som exporteras med viss frekvens i sin helhet, t.ex. ett register från ett produktinformationssystem (PIM) som exporteras till fil en gång per dygn (ofta någon typ av textfil i komma-separerat format – CSV).
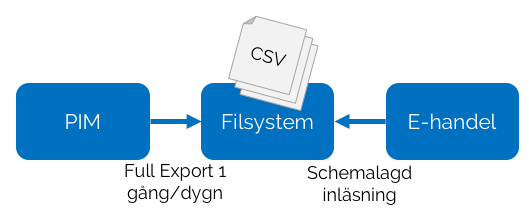 För det allra mesta är man intresserad enbart av förändringar, men bearbetar ändå hela registret, där kanske 95% av all information egentligen är helt ointressant. Inom bland annat e-handel är detta särskilt problematiskt, eftersom man typiskt också indexerar innehållet för att erbjuda sökfunktionalitet, så varje hanterad post medför beräkningsintensiv och tidskrävande bearbetning. Egen erfarenhet från ett tidigare projekt handlade om att bearbeta en artikelexport med omkring 40.000 poster, vilket tog runt 8 timmar i anspråk. Efter att ha ändrats enligt den lösningsbeskrivning som följer kunde samma jobb hanteras på några minuter.
För det allra mesta är man intresserad enbart av förändringar, men bearbetar ändå hela registret, där kanske 95% av all information egentligen är helt ointressant. Inom bland annat e-handel är detta särskilt problematiskt, eftersom man typiskt också indexerar innehållet för att erbjuda sökfunktionalitet, så varje hanterad post medför beräkningsintensiv och tidskrävande bearbetning. Egen erfarenhet från ett tidigare projekt handlade om att bearbeta en artikelexport med omkring 40.000 poster, vilket tog runt 8 timmar i anspråk. Efter att ha ändrats enligt den lösningsbeskrivning som följer kunde samma jobb hanteras på några minuter.
Kontext
För att vara relevant kräver lösningen att vissa omständigheter föreligger:
- Källdatasystemet ligger utanför vår kontroll och går inte att påverka eller ändra inom ramen för rimliga kostnader, så enbart befintliga integrationsgränssnitt kan användas.
- Datamängden är förhållandevis stor och antalet ändringar är proportionellt lågt sett över tiden.
- Mottagande system lider av att en frekvent återkommande, total inläsning av källdata, tar tid och resurser i anspråk
Målsättningen är att bara behöva behandla data som faktiskt är förändrad – d.v.s. extrahera ett ”delta” ur totalen som motsvarar nya eller förändrade poster.
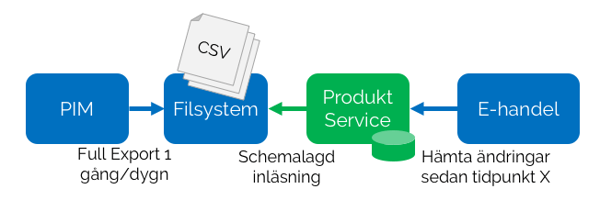
Lösningen bygger på att man inför ett mellanled – en ny tjänst – som tar hand om importen av totalfilen och som utifrån denna kan leverera enbart den delmängd av information som förändrats (delta) sedan förra utläsningstillfället. Den nya tjänsten håller en egen läskopia av registret i någon form av databas.
Inläsning
Inläsning av den nya tjänsten sker typiskt utifrån exakt samma förutsättningar som tidigare, t.ex. genom ett schemalagt jobb som regelbundet kontrollerar om en ny exportfil finns. Om en ny fil dykt upp sedan sist påbörjas inläsning av densamma, och innehållet bearbetas rad för rad.
Identifiera förändring
En central finess med lösningen är hur ändringar identifieras och detta sker genom användning av en hashningsalgoritm (t.ex. MD5 eller SHA1). En hash kan ses som en digital signatur av given indata och det är extremt osannolikt att två olika indata producerar samma hash. Detta faktum kan vi använda för att identifiera om en post i registerexporten är förändrad jämfört med föregående inläsningstillfälle.
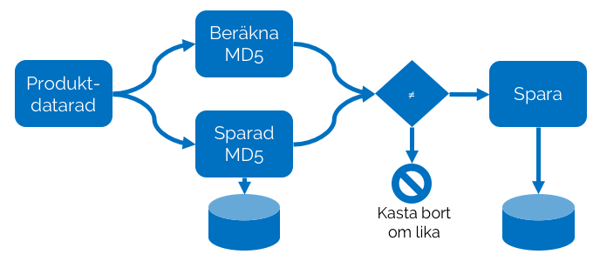
Inläsningen sker enligt följande process för varje rad i registerexporten:
- Läs in och slå samman alla attribut i en sträng och beräkna hash-värdet för strängen.
- Slå upp hash-värdet för tidigare lagrad datapost
- Om de två värdena är lika har ingen förändring skett – hoppa direkt till nästa rad
- Om de två värdena däremot är olika har en förändring skett sedan föregående inläsningstillfälle. Spara den uppdaterade raden tillsammans med tidpunkt och det nya hash-värdet.
En datamodell för hur lagring kan ske ges av nedanstående tabell.
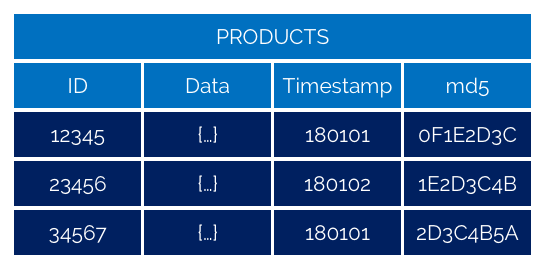
I detta sammanhang kan det vara lämpligt att lagra informationen serialiserad (t.ex. i form av JSON). Det finns ingen anledning att bryta upp informationen i någon normalform eftersom lagringen enbart används för att tillhandahålla delta till konsumerande delsystem. Därför är det lämpligt att lagra informationen på precis det format man tänker sig att anropande system kommer att erhålla den.
Utläsning
Eftersom varje förändring nu är lagrad med tillhörande tidpunkt då förändringen skedde kan man enkelt från konsumerande sida hämta bara de poster som förändrats.
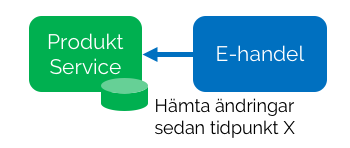
Typiskt realiseras detta i form av en tjänsteändpunkt som tar en tidpunkt som argument och returnerar alla poster som är lagrade med en nyare tidstämpel än denna. Anropande system kan då periodvis anropa tjänsten med tidpunkten för senaste körning som argument. Skulle man av någon anledning behöva grundladda, eller återställa hela registerinformationen behöver man bara anropa tjänsten med tidpunkt ’0’ som argument, så får man automatiskt det kompletta registerinnehållet som svar.
Microservice-arkitektur
Även i en miljö som i övrigt är uppbyggd som en monolitisk applikation passar funktionen att implementeras i form av en mikrotjänst. Inkapslad, utan explicita beroenden och hanterar sin egen data. Datalagret behöver inte vara en traditionell SQL-databas, utan kan med fördel bestå av en dokumentdatabas, eller något ännu enklare som t.ex. en key-value-store.
Utmaningar
En utmaning som kan uppstå är att man behöver utföra någon typ av tillägg bland attributen i systemet. Beroende på hur detta utformas kan det innebära att alla poster kommer att identifieras som förändrade, även om det nya attributet bara används för en delmängd av alla poster. Om en komplett registerinläsning inte medför något stor störning på den normala driften kan man kanske ta med detta som en kalkylerad risk. Annars måste man säkerställa att bara de attribut som faktiskt har något värde för en given post ingår i beräkningen av hashen.
Ett annat potentiellt problem kan uppstå om avsaknad av poster i källexporten är indikation på att de är borttagna. Generellt sett är det alltid bäst om man kan flagga att en post är borttagen än att bara ta bort den, men om det inte går måste man läsa in ID för alla tidigare lagrade poster, beräkna differensen av denna och alla ID som förekommer i exportfilen och markera motsvarande poster som borttagna i den lokala datakällan. Den främsta anledningen till att detta inte är en önskvärd hantering är att en av misstag trunkerad fil innebär att man tar bort poster, och i extremfallet: Om exportfilen är tom tar man bort samtliga poster. Under dessa omständigheter bör man bygga in någon typ av validering av indata (t.ex. minsta antal rader eller kontroll att sista tecken i filen är en radbrytning).
Ytterligare möjligheter
Om man väljer att göra posterna i databasen oföränderliga ”immutable”, och vid varje förändring skapa en ny post med ett uppräknat generationsnummer kommer man att kunna se ”bakåt i tiden” – d.v.s. kunna utläsa hur informationen såg ut vid en given tidpunkt. I praktiken har man då byggt en lösning enligt mönstret ”event-sourcing” som har många positiva egenskaper.

