
Självbetjänande dataflöden och analyser
I dagens samhälle finns data överallt. Hur många av oss har inte följt vädret på SMHI/YR eller Klart i sommar. Många av oss skannar eller väljer självbetjänande kassor på ICA, Hemköp, eller IKEA. Vi får digitala kvitton och räkningar på Kivra. Data som ibland behöver följas upp och analyseras.
I företagsvärlden har vi olika system för ekonomi, hr, produktion och crm samt en mängd andra databaser eller annan data från givare, webb eller appar..
För att sammanställa den privata informationen använder de flesta Excel. Det finns cirka en miljard excelanvändare i världen. Excel är fantastiskt på små beräkningar, analyser eller på att se och förstå data. Så Excel är självbetjäning fullt ut. För att arbeta med lite mer avancerad Excel kan man utöka produkten med makron, PowerQuery, eller PowerBI. Med PowerBI kan man hantera större datamängder och bygga dataflöden till dataset som sedan kan visualiseras snyggt på webben.
Nästa nivå av självbetjäning är uppdelning av data och dataflöden i flera steg. Data hämtas in från olika Excel/databaser/datalager/datalakes eller andra källor. Där samlas den upp och inväntar annan data innan den förädlas vidare eller konsolideras. Ungefär som på en tågstation eller i ett kök.
Då blir spårbarheten, överblickbarheten av dataflödena viktiga.
Data behöver dessutom formateras, tvättas och kvalitetssäkras för att den skall leverera rätt nyckeltal eller få rätt detaljeringsgrad(upplösning). När den bearbetats färdigt håller den rätt kvalitet och genererar ett högt värde.
Skall den delas eller levereras till olika användargrupper vill man även gruppera och organisera upp den i ämnesområden såsom produkt, kund, organisation, geografi, datum eller konton/projekt.
Då vill man då också automatisera sina flöden med schemaläggning.
Inom Business Intelligence har man länge gjort detta med IT-verktyg såsom Microsoft SSIS, Datafactory, Informatica, OracleData Integrator, Matillion, Wherescape, TimeXtender,Data Stage eller open source såsom Airflow/DBT.
Ovan produkter är bra, kan göra det mesta men kräver en del utbildning och datateknikkunskap.
Självbetjäning inom data & analys har sedan länge drivits framåt av Tableau. De har sedan starten haft en bredare målgrupp och fokuserat på att göra data arbete enkelt och visuellt snyggt. Alla skall se och förstå sin data.
I den senaste versionen av Tableau Creator har man tagit ett nytt steg inom självbetjäning. Tableau Creator innehåller både visualisering, möjlighet att dela data på server i moln eller lokalt samt självbetjänad dataförberedelse. Delad data kan sedan analyseras och filtreras av andra användare eller delas på webben.
I Tableau dataprep kan således alla bygga sina dataflöden. Det ger full spårbarhet visuellt vilket gör det lätt att förstå alla steg i bearbetningsprocessen och i analysen. Nu kan man även själv bygga upp sitt datalager med Tableau prep.
Här kommer ett exempel från våra tidrapporter. Som konsultbolag registreras vanligtvis tiden både hos kund och internt. Jag behöver följa upp tiderna för olika projekt och göra avstämningar innan fakturering.
Steg ett: Hämta tidrapport data från vårt px I tabellen PXtimeaccounthour. Jag väljer att titta på data efter 2018 där konsulterna har rapporterat några timmar.
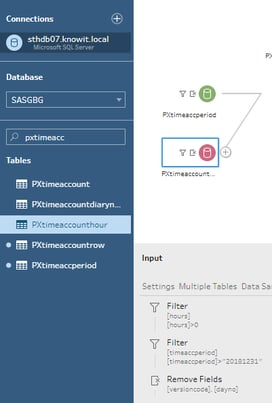
Steg två: Jag vill analysera data över perioder så jag hämtar data från pxtimeaccperiod och koppla samman den med PXtimeaccounthour med datumkolumnen.
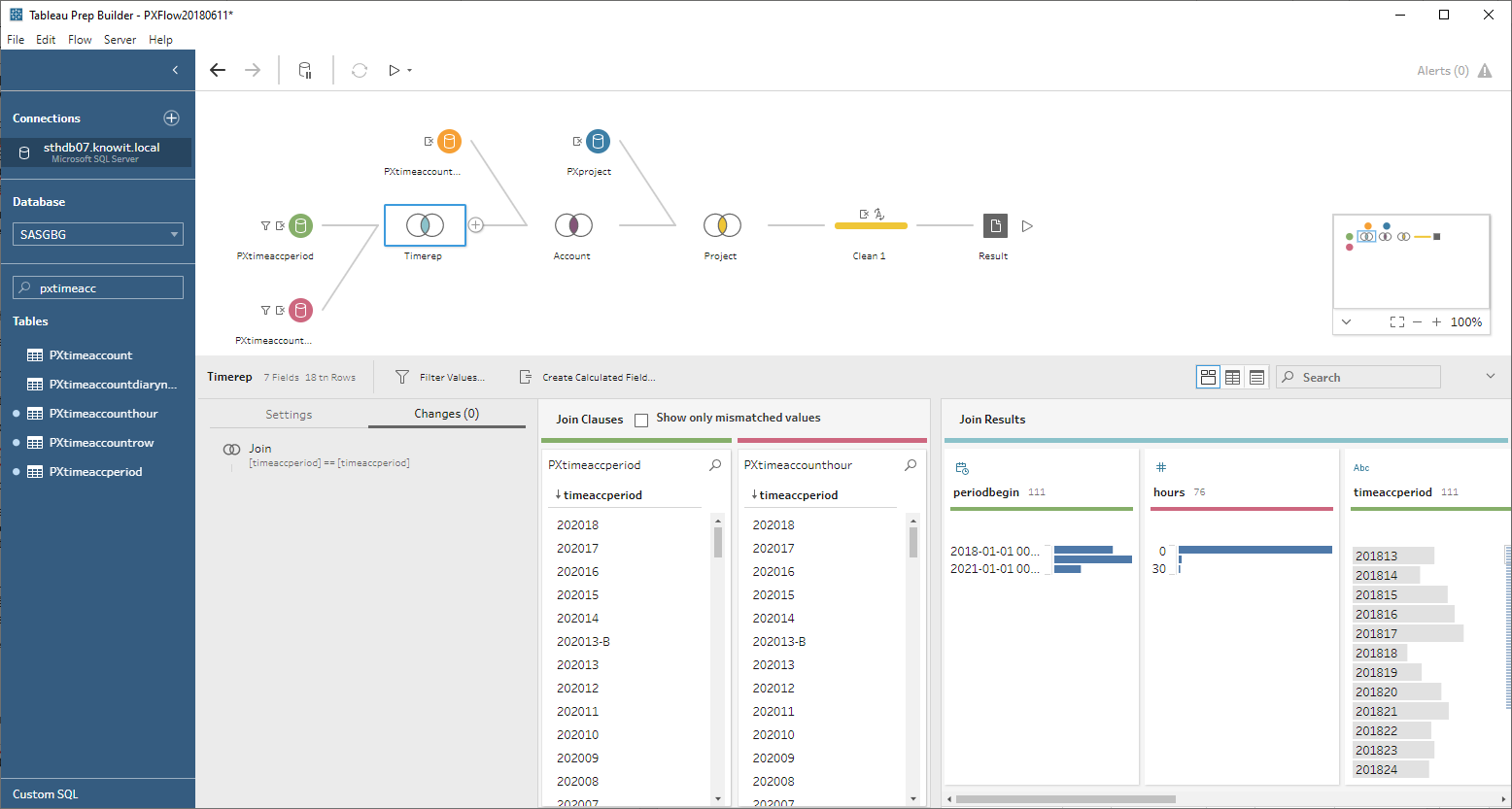
Steg tre: Behöver även priser och kontouppgifter och projektuppgifter som jag hämtar från PXtimeaccountrow och PXProject.
Nu har jag ett dataset som jag vill snygga till med en tvätt innan jag lägger in det för delning i databasens datalake eller landningsarean för datalagret.
När jag har gjort klart laddningsflödet vill jag lagra data säkert och återanvändbart.
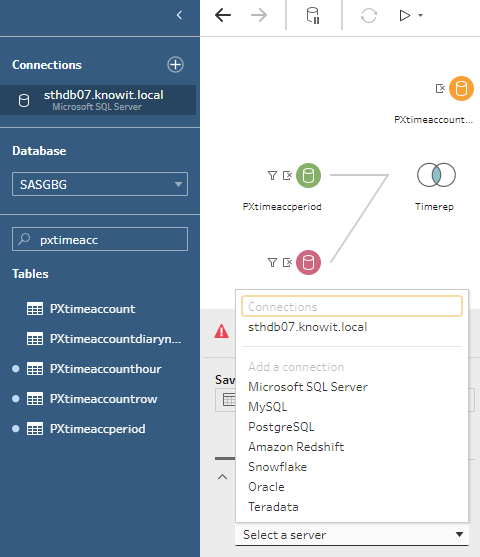
Som ni ser ovan kan lagringen vara en databas såsom SQLServer, MySQL, PostgreSQL, Redshift, Oracle, Teradata eller Snowflake. Jag kan också spara till fil eller till ett Tableau dataset.
Jag väljer data plattformen Snowflake för att den är självoptimerande och väldigt enkel att sätta upp och hantera. Där kan också dela tabellen eller dataset eller skapa vyer till olika användargrupper på ett smart och smidigt sätt. Att få upp data i en databas som är anpassad för analys gör att jag även kan styra prestandan för olika användningsområden och betala för det jag använder.
Detta stöd gör att jag själv får kontroll och kan styra över min tvättade data och följa flödet. I Tableau online kan jag också sätta upp när dataflödet skall köras.
På detta sätt kan jag själv automatisera mina datahämtningar och skapa mitt eget datalager med fullt historiestöd och fullt anpassad för analys. I en flerstegslösning kan jag även dimensionsmodellera data och ta hand om inkrementella laddningar eller andra förändringar I datamängderna. Det kan ju vara så att jag vill följa upp organisationsförändringar eller andra händelser.
Den färdigbakade datan använder jag och andra sedan I Tableau för analys.
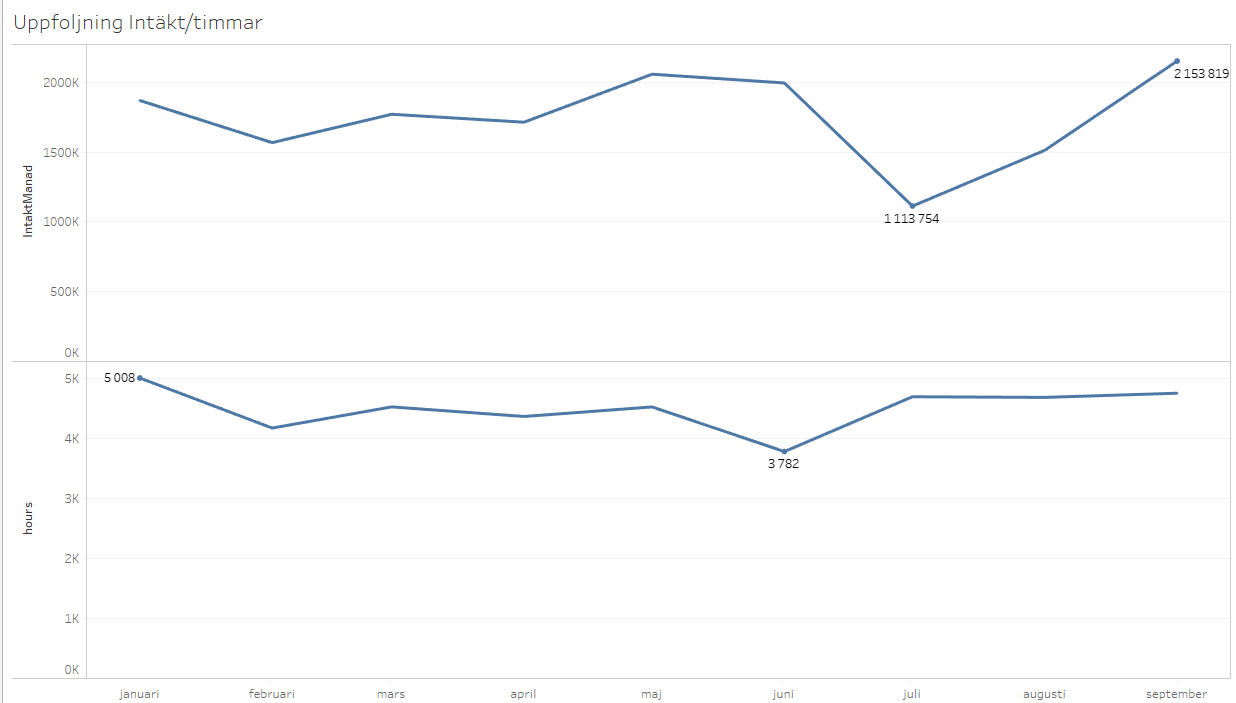
För många känns det väldigt bra att kunna ha kontroll på sin data och kunna följa den hela vägen.
Så jag ser manga användningsområden för självbetjänad analys från Ax till Limpa.
Vill ert bolag också arbeta strukturerat med självbetjänad analys så har vi på Knowit metoder och etableringsprogram för detta..
Kontakta mig
Håkan Alsén
0738 47 28 00
Hakan.alsen@knowit.se


