
Nu ska vi se hur data science ser ut på djupet och kan hjälpa till att bygga en smart stad. Vi tar steget vidare från förra inläggets översiktliga analys och visar hur en geografisk analys av cykelstationerna i Styr & Ställ i Göteborg kan se ut. Detta inlägg är en del av vår serie om data science i praktiken. Läs gärna först inledningen och tillgänglighetsanalysen vilka ger perspektiv och visar var data kommer från.
Vad gör en cykelstation populär?
Är cykelstationerna rätt placerade? Vad påverkar hur populär en station blir? Var skulle vi behöva nya? Hur blir Göteborg en smart city? För att svara på detta väver vi in öppna kartdata, visar hur en geospatiell analys går till och tillämpar maskininlärning för att bygga en modell av var stationer behövs. Naturligtvis blir det också en del visualisering så att vi ser vad vi gör. Varför inte börja med en bild över alla stationer och vilken yta systemet täcker idag.
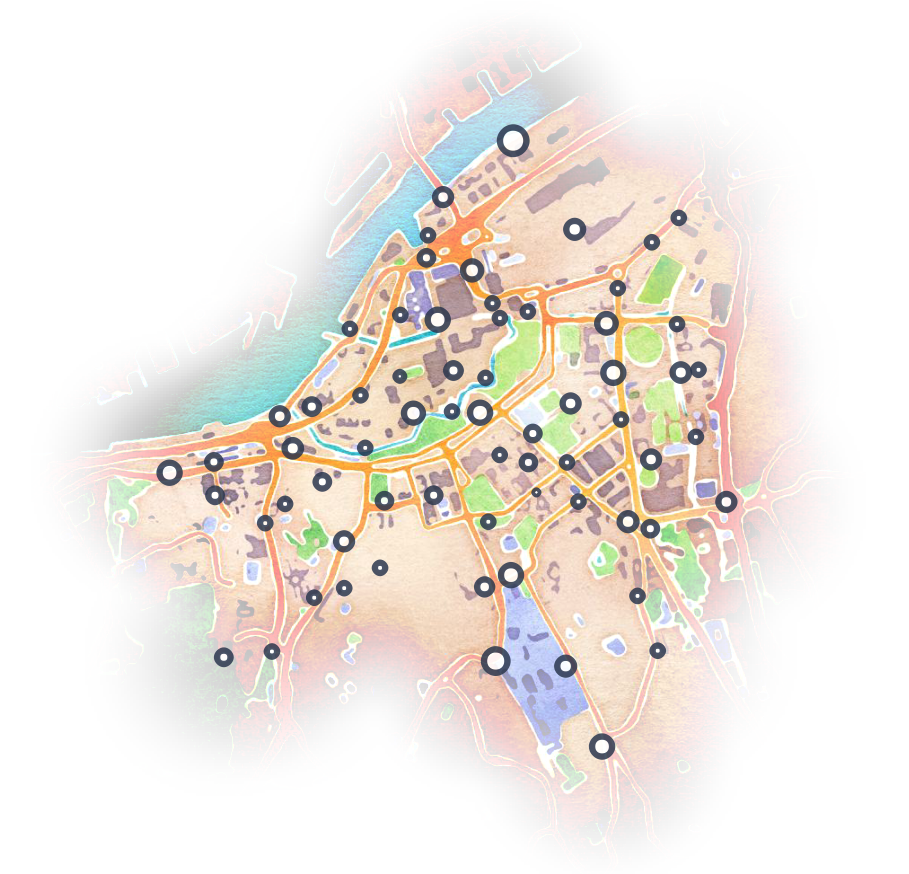 Bilden visar cykelstationerna i Styr & Ställ och vilken del av staden de täcker. Stationens storlek motsvarar kapaciteten (antal cykelställ).
Bilden visar cykelstationerna i Styr & Ställ och vilken del av staden de täcker. Stationens storlek motsvarar kapaciteten (antal cykelställ).
Öppna data är nyckeln
Vi vill undersöka cykelstationernas geografiska placering och då är det avgörande att vi kan sätta dem i ett sammanhang. Ligger stationen nära en busshållplats? Finns det många affärer och caféer i närheten? Ligger den vid en stor knutpunkt? Här behöver vi kartdata. En nyckel för data science är att börja med öppna data för att visa möjligheter och veta hur bra det måste vara – ett riktmärke. Duger inte kvaliteten på de öppna data kan man överväga att betala för bättre. Men då vet man värdet av vad man köper.
Färdighet #7: öppna data
Open Street Map
En data scientist är inte mycket utan data och verktyg. För öppna kartdata är Open Street Map (OSM) det självklara valet och vi plockade ut ett extrakt för Göteborgsområdet. OSM är ett ideellt projekt för framtagning av geografisk information där vem som helst kan lägga till och ta bort kartobjekt – ungefär som på Wikipedia. Hur mycket data handlar det om? Tittar vi inom fem kilometers radie från Avenyn i Göteborg ser vi att OSM har omkring 14 000 punkter (busshållplatser, träd, caféer, mm.), 11 000 linjer (vägar, gränser, spårvagnar, mm.) och 9 000 polygoner (byggnader, markytor, mm.). I bilden här under ser vi ett urval av Styr & Ställ-stationerna tillsammans med olika kartobjekt.
Färdighet #8: kartdata
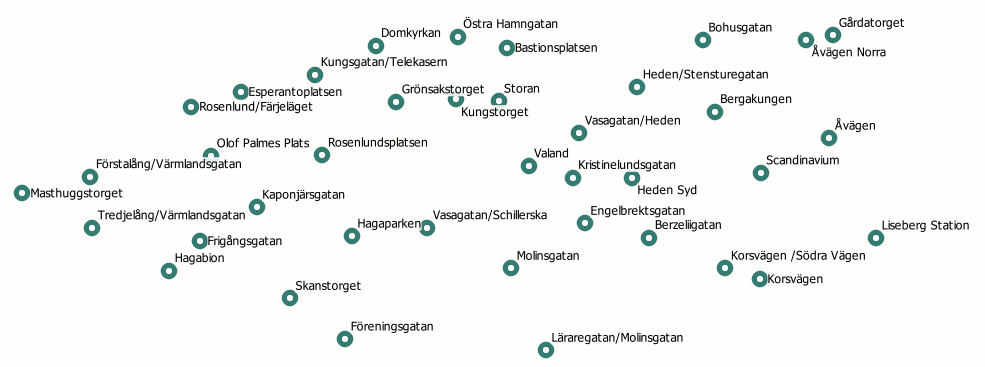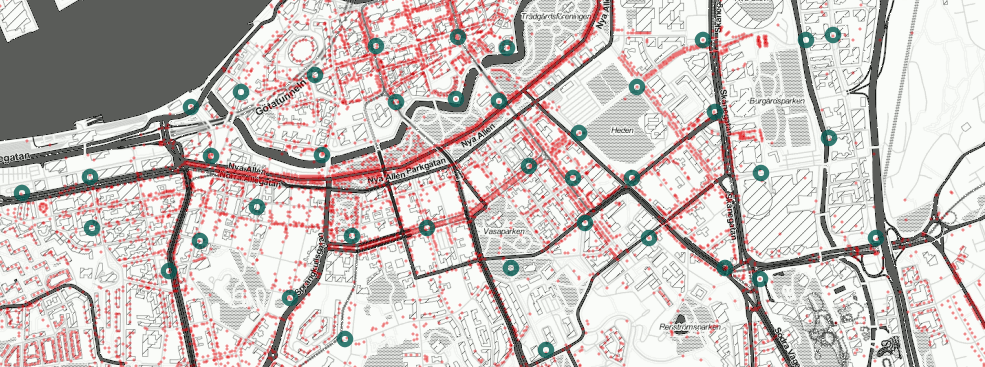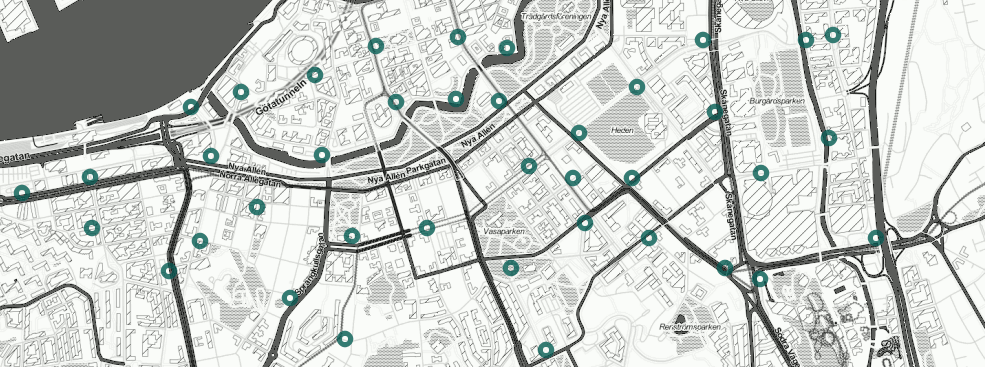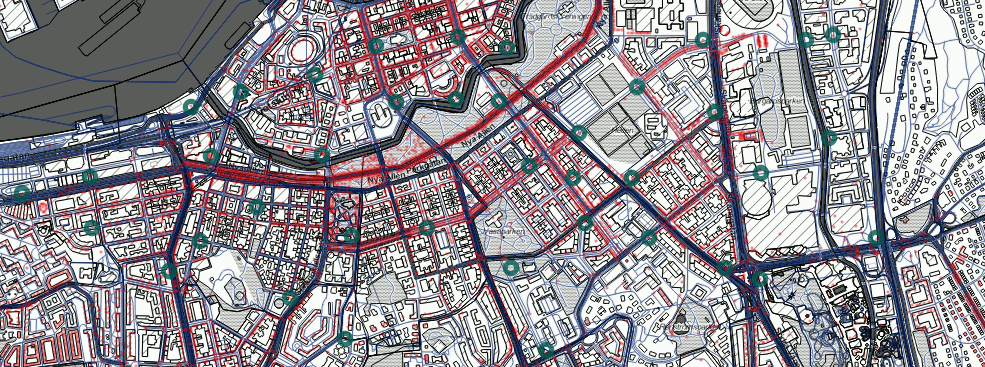
Maskininlärning och attribut
Vi vill förstå vad som gör en station populär, det vill säga används mycket. För att bygga en modell tar vi hjälp av maskininlärning (ML), vi låter alltså datorn söka efter mönster i kartdata kring stationerna. Det första steget inom ML blir att ta fram alla tänkbara attribut (features) som beskriver stationerna och som kan tänkas påverka deras popularitet. Antalet ställ i stationen är till exempel ett givet attribut att titta på. I övrigt brainstormar vi fram runt hundra attribut från kartdata 200 meter kring stationen: antal vägar, korsningar, busshållplatser, cykelvägar, statyer, caféer, byggnader, och så vidare. Nästa steg är att avgöra vilka av dessa attribut som innehåller intressanta mönster och beskriver popularitet.
Färdighet #9: maskininlärning
Verktygen för analys av kartdata hittar vi inom domänen geografiska informationssystem (GIS). GIS-verktyg ger oss metoder för spatiell indexering, mappning och analys av olika geografiska objekt och lager. Det är en av många tekniker en data scientist har i sin verktygslåda (eller snabbt skaffar sig vid behov).
Färdighet #10: Geographical Information Systems (GIS)
Cykelvägar skapar inte populära stationer
Efter att prövat olika metoder för analys av attribut landar vi i en bra bild. Som så ofta blir man förvånad över vilka de viktiga parametrar är. Det visar sig att antalet cykelvägar kring en station inte alls påverkar hur populär den är. Inte heller antalet pubar, förbipasserande busslinjer eller offentliga toaletter. Antalet ställ i stationen var däremot den tredje viktigaste faktorn och närhet till busshållplats inte långt därefter. De två absolut viktigaste faktorerna för hur populär en station är hittade vi i kartdata. Gissa vilka? Här bör vi poängtera att den prediktiva styrkan kommer av kombinationen av flera attribut. Det finns heller inget som säger att dessa attribut alltid skapar populära stationer – vi tittar på en begränsad mängd stationer för ett mindre område.

En modell för stationens popularitet
Med de bättre av våra attribut bygger vi en ickelinjär regressionsmodell som beskriver popularitet utifrån geografisk placering. I det här fallet får vi mycket intressanta resultat med metoden Random Forest (en mängd beslutsträd tränas på delmängder av data och fattar sedan beslut som sammanvägs). Vi utelämnade naturligtvis en slumpmässig grupp stationer för att utvärdera modellen. Dessa så kallade testdata visar att vi tydligt fångar trender men ibland avviker ett tiotal procent. Det känns rimligt med tanke på att varje station är unik och att vi här inte fördjupat oss nämnvärt i attributval.
Färdighet #11: prediktiv modellering
Var borde cykelstationerna ligga?
Vi har nu en modell över popularitet och den kan användas överallt där vi har kartdata. I detta fall är vi begränsade till de öppna data i Open Street Map men låt oss göra ett försök. Vi skapar ett stort fint rutnät över Göteborg och utvärderar modellen för varje punkt. Med ett färgdiagram (heat map) kan vi enkelt se hur populär en station skulle bli utifrån var den placeras. Det visar var stationer behövs och vi märker till exempel direkt att en station vid korsningen Framnäsgatan/Mölndalsvägen kunde vara intressant. Idag finns Styr & Ställ endast i centrum men många har efterfrågat en utvidgning till Hisingen. Här under visas en utvärdering från delar av ön där man tydligt ser röda områden där en station skulle bli populär.
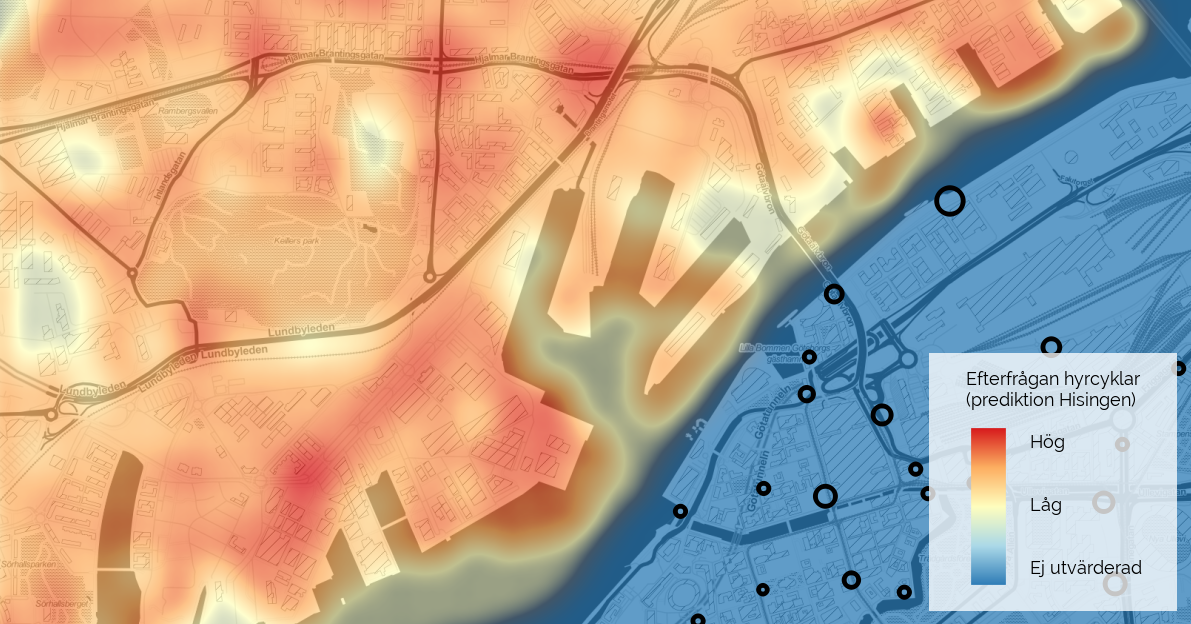
Färgdiagrammet är helt data-drivet genom maskininlärning och GIS. Det bygger alltså på vår modell och de faktorer i kartdata som gör dagens stationer populära. För tydlighets skull har vi uteslutit områden på fastlandet där vi redan har stationer idag. Den som kan sitt Hisingen ser att vår regressionsmodell ger en rimlig indikation på var stationer kan vara populära. Naturligtvis måste man göra en fördjupad analys för att verkligen fastlägga att modellen är korrekt och att alla viktiga attribut är med. En av de viktigaste faktorerna för ett cykelsystem är till exempel vilken höjd stationerna ligger på. Hur ofta en station blir full eller tom är en annan faktor att ta med i modellen.
Avancerad analys gör det möjligt!
Syftet med detta exempel är att visa hur data science och avancerad analys kan bygga värde och ta fram nya insikter. Vi har sett hur viktigt det är med öppna data, GIS-verktyg och maskininlärning för att bygga en smart stad. Även om vi här framförallt visar data science översiktligt blir det tydligt hur man kan förbättra sin verksamhet om man börjar arbeta data-drivet. Och det behöver inte handla om geografiska data eller öppna data för att vara möjligt. Vill du ha mer inspiration och stöd för att själv snabbt komma upp på banan?
Läs mer:
Del 1 – Data Science i praktiken
Del 2 – Hur tillgängligt är Styr & Ställ?
Del 4 – Hur data science kan rädda miljön
The Data Scientist


